Ultra Fast Metropolis-Hastings Algorithm in High Dimensions
Sampling distribution over high-dimensional state-space has
recently attracted a lot of research efforts in computational
statistics and machine learning community.
Most of the sampling techniques known so far do not scale to
high-dimension and become impractical when the number of data
samples is huge (big data).
The Metropolis Adjusted Langevin Algorithm is a more general
purpose markov chain monte carlo algorithm for sampling from
a differentiable target density.
Introduction
Locate where the .RData file was saved.
On a MacBook, this can be done by right-clicking on the file and choosing the 'Get Info' option.
Review of Metropolis-Hastings Algorithm
The Metropolis-Hastings (MH) algorithm is routinely used to generate
samples from a target distribution, denoted $p(\mathbf{x})$, that may
otherwise be difficult to sample from (Metropolis et al. 1953;
Hastings 1970).
The MH algorithm works by generating a Markov Chain, whose stationary
distribution is the target distribution. This means that, in the long run,
the samples from the Markov chain will look like the samples from the
target distribution, i.e., we use a Markov chain to generate a sequence
of vectors, denoted $(\mathbf{x}_0, \mathbf{x}_1, \ldots, \mathbf{x}_M)$
such that as $M \rightarrow \infty, \mathbf{x}_M \sim p(\mathbf{x})$.
The sequential steps involved in MH algorithm are as follows:
Initialize the chain.
For $m = 1, 2, \ldots, M,$ to generate the next vector in the chain
$\mathbf{x}_m \in \mathbb{R}^n$, sample a candidate vector $\mathbf{x}^*$
from a proposal (conditional) distribution $q(\mathbf{x}^* | \mathbf{x}_{m - 1})$,
which is a distribution that is fairly easy to generate values from.
Note that the word "conditional" in the context of the proposal distributions
in the MH algorithm just means that the mean of the proposal
distribution will be set to the value of the conditioning parameter,
which in this case is $\mathbf{x}_{m - 1}$.
Compute the
acceptance probability using the formula:
$$A = \min \left\{1, \frac{p(\mathbf{x}^*) q(\mathbf{x}_{m - 1} | \mathbf{x}^*)}{p(\mathbf{x}_{m - 1}) q(\mathbf{x}^* | \mathbf{x}_{m - 1})} \right\}.$$
When $q(\mathbf{x})$ is symmetric,
the formula simplifies to:
$$A = \min \left\{1, \frac{p(\mathbf{x}^*)}{p(\mathbf{x}_{m - 1})} \right\}.$$
Generate a uniformly distributed random number between 0 and 1, denoted $u$.
The acceptance or rejection decision of the candidate vector $\mathbf{x}^*$
as a new member of the chain can be done using the following criteria:
$$\mathbf{x}_m = \begin{cases}
\mathbf{x}^*, \quad \quad \; \text{ if }u \leq A, \\
\mathbf{x}_{m - 1}, \quad \text{ otherwise.}
\end{cases}$$
Implementing a Metropolis-Hastings Algorithm in R
Suppose we want to generate a zero-mean 2-dimensional (2D)
spatial Gaussian random field from an
exponential spatial covariance function model on a $50 \times 50$ grid
on the unit square similar to the 2D spatial Gaussian random field in
Figure 1 below.
Figure 1: Sample 2D spatial Gaussian random field on a 50 $\times$ 50 grid on the unit
square generated from an exponential spatial covariance function model.
Despite having a straightforward and convenient way to generate samples
from the multivariate Gaussian distribution, the MH algorithm is also
an alternative way to accomplish the required task. Doing so will also
be a good exercise in showing the novelty of the MH algorithm in generating samples
from a target distribution. In the following, a
step-by-step implementation from scratch of the MH algorithm in
R is illustrated.
Specify the target distribution $p(\mathbf{x})$.
We want to generate samples $\mathbf{Z} = \{ Z (\mathbf{s}_1),
\ldots, Z (\mathbf{s}_{n}) \}^{\top} \in \mathbb{R}^{n}$
where $Z (\mathbf{s})$ is the value at spatial location
$\mathbf{s} \in \mathbb{R}^{d}$. Here $n$ is the number of spatial
locations and $d$ is the dimension of the spatial location.
In the 50 $\times$ 50 grid example above, the value of $n$ is 2,500.
For flat surfaces where spatial locations are defined by
the position along the $x$ and $y$ axes, the value of $d$ is 2.
The following R codes show how
to generate a 50 $\times$ 50 grid:
To visualize the grid, the following R
codes show the x and y axes and plot the locations we constructed above.
plot(locs, pch = 20, xlab = '', ylab = '')
mtext(expression(s[x]), 1, line = 2)
mtext(expression(s[y]), 2, line = 2)
The following plot should appear on the bottom-right portion of
your RStudio session.
Figure 2: 50 $\times$ 50 grid on the unit square.
The $s_x$ notation in the plot above indicates the $x$-coordinate
of location. Similarly, $s_y$ indicates the $y$-coordinate.
We want $\mathbf{Z}$ to come from a multivariate Gaussian
distribution. If $\mathbf{Z}$ is from a multivariate Gaussian
distribution, we write $\mathbf{Z} \sim \mathcal{N}_{n}
(\boldsymbol{\mu}, \boldsymbol{\Sigma})$, where $\boldsymbol{\mu}$
is the $n \times 1$ mean vector of $\mathbf{Z}$ and $\boldsymbol{\Sigma}$
is the $n \times n$ covariance matrix of $\mathbf{Z}$. This means
that $$\text{E}(\mathbf{Z}) = [ \text{E}\{Z (\mathbf{s}_1)\}, \ldots,
\text{E}\{Z (\mathbf{s}_{n})\}]^{\top} = \{ \mu (\mathbf{s}_1), \ldots,
\mu (\mathbf{s}_{n}) \}^{\top} = \boldsymbol{\mu} \quad \text{ and }$$
$$\begin{bmatrix}
\text{cov}\{Z (\mathbf{s}_1), Z (\mathbf{s}_1)\} & \text{cov}\{Z (\mathbf{s}_1), Z (\mathbf{s}_2)\} & \cdots & \text{cov}\{Z (\mathbf{s}_1), Z (\mathbf{s}_n)\} \\
\text{cov}\{Z (\mathbf{s}_2), Z (\mathbf{s}_1)\} & \text{cov}\{Z (\mathbf{s}_2), Z (\mathbf{s}_2)\} & \cdots & \text{cov}\{Z (\mathbf{s}_2), Z (\mathbf{s}_n)\} \\
\vdots & \vdots & \ddots & \vdots \\
\text{cov}\{Z (\mathbf{s}_n), Z (\mathbf{s}_1)\} & \text{cov}\{Z (\mathbf{s}_n), Z (\mathbf{s}_2)\} & \cdots & \text{cov}\{Z (\mathbf{s}_n), Z (\mathbf{s}_n)\}
\end{bmatrix} = \begin{bmatrix}
\Sigma_{11} & \Sigma_{12} & \cdots & \Sigma_{1n} \\
\Sigma_{21} & \Sigma_{22} & \cdots & \Sigma_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
\Sigma_{n1} & \Sigma_{n2} & \cdots & \Sigma_{nn} \\
\end{bmatrix} = \boldsymbol{\Sigma}.$$
Code the mean of the target distribution.
We want $\mathbf{Z}$ to be zero-mean, meaning we
set $\boldsymbol{\mu}$ to be the zero vector. In R,
this can be done as follows:
mu <- rep(0, n.loc)
The R variable
mu above is a vector consisting of
2,500 zeros. Printing the values of mu
on the R console will look like this:
Figure 3: Mean vector of $\mathbf{Z}$.
Code the covariance of the target distribution.
We want the covariances between the components of $\mathbf{Z}$,
namely, $Z (\mathbf{s}_1), Z (\mathbf{s}_2), \ldots, Z (\mathbf{s}_n)$,
to be modeled by the exponential spatial covariance
function. This means that
$$\text{cov}\{Z (\mathbf{s}_i), Z (\mathbf{s}_j)\} =
\sigma^2 \exp \left( -\frac{\|\mathbf{s}_i - \mathbf{s}_j \|}{a} \right),$$
where $\sigma^2$ and $a$ are the nonnegative parameters of the
exponential spatial covariance function. Here, $\sigma^2$ is the
variance parameter, while $a$ is the spatial range parameter.
You can set the values of these parameters to any nonnegative value.
However, note that the parameter values will control the statistical
properties of the $\mathbf{Z}$ that will be generated later on.
The following R codes set the parameter values
equal to the ones used to generate the $\mathbf{Z}$ values
in Figure 1.
sigma2 = 1
a = 0.5
The symbol $\| \cdot \|$ indicates that we need to solve for
the Euclidean distance between locations $\mathbf{s}_i$ and $\mathbf{s}_j$.
Remember that the Euclidean distance can be computed using the formula:
$$ \|\mathbf{s}_i - \mathbf{s}_j \| = \sqrt{(s_{i1} - s_{j1})^2 +
(s_{i2} - s_{j2})^2 + \ldots + (s_{id} - s_{jd})^2}.$$
When $d = 2$, meaning we only have the $x$ and $y$ axes to describe the
location, the Euclidean distance formula simplifies to:
$$ \|\mathbf{s}_i - \mathbf{s}_j \| = \sqrt{(s_{ix} - s_{jx})^2 +
(s_{iy} - s_{jy})^2}.$$
Given a matrix of locations such as locs,
the distance between any two locations can be computed systematically
using the R function
dist().
This can be done as follows:
dist_matrix <- as.matrix(dist(locs))
Note that dist_matrix is a
2,500 $\times$ 2,500 matrix of distances, where the
$i$th and $j$th entry of the matrix is the Euclidean distance
between locations $\mathbf{s}_i$ and $\mathbf{s}_j$.
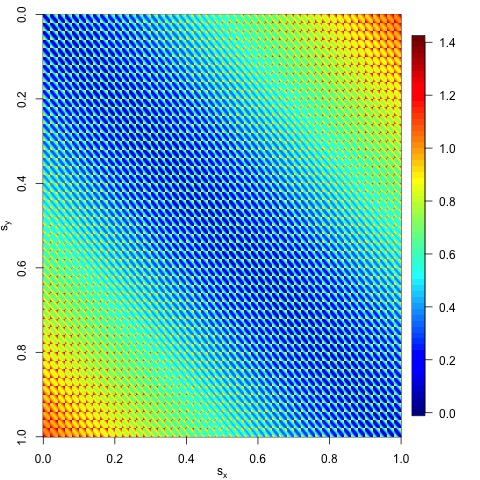
We can visualize the distances by plotting an image of the
dist_matrix using the
image.plot() function in the
R package fields.
The following codes detail how this can be done in
R:
install.packages("fields")
library(fields)
image.plot(dist_matrix, ylim=c(max(locs[, 2]),0))
mtext(expression(s[x]), 1, line = 2)
mtext(expression(s[y]), 2, line = 2)
The following plot should appear on the bottom-right portion of
your RStudio session.
Figure 4: A heatmap of the distances between any two
locations.
Now that we have the parameter values and the distances,
we can now compute the values of the entries inside the covariance matrix
$\boldsymbol{\Sigma}$. The covariance matrix can easily be computed
with one line of R code as follows:
cov_matrix <- sigma2 * exp(-dist_matrix/ a)
The code above simply executes the formula for the
exponential covariance function. Note that
cov_matrix is a
2,500 $\times$ 2,500 matrix of covariances, where the
$i$th and $j$th entry of the matrix is the value of the exponential
covariance function evaluated with locations $\mathbf{s}_i$ and $\mathbf{s}_j$.
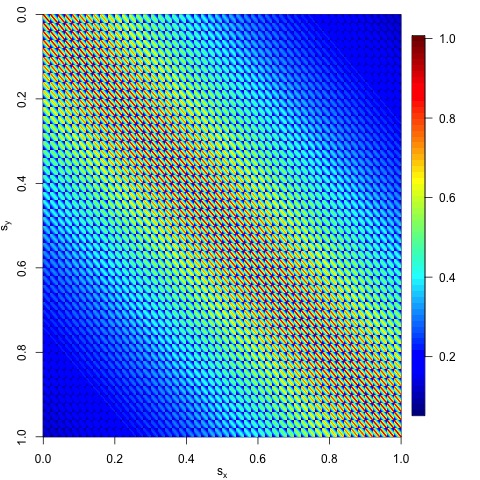
We can visualize $\boldsymbol{\Sigma}$ by plotting an image of the
cov_matrix as follows:
image.plot(cov_matrix, ylim=c(max(locs[, 2]),0))
mtext(expression(s[x]), 1, line = 2)
mtext(expression(s[y]), 2, line = 2)
The following plot should appear on the bottom-right portion of
your RStudio session.
Figure 5: A heatmap of the values inside the covariance matrix
$\boldsymbol{\Sigma}$.
Code the function that will compute
the density of the target distribution.
Given the mean vector mu
and the covariance matrix cov_matrix,
we can now code a function that will compute the density of our
target distribution. The multivariate Gaussian density has the form:
$$p(\mathbf{z} | \boldsymbol{\mu}, \boldsymbol{\Sigma}) =
\frac{1}{(2 \pi)^{n/2} |\boldsymbol{\Sigma}|^{1/2}} \exp \left\{
-\frac{1}{2} (\mathbf{z} - \boldsymbol{\mu})^{\top}\boldsymbol{\Sigma}^{-1}
(\mathbf{z} - \boldsymbol{\mu})\right\}, $$
where $\mathbf{z}$ is any vector in $\mathbb{R}^n$.
In practice, we often work with the logarithmic transformation of the
multivariate Gaussian density. This makes it easier for computers to store
and handle very small probability values. The multivariate Gaussian log
density has the form:
$$\ln \{ p(\mathbf{z} | \boldsymbol{\mu}, \boldsymbol{\Sigma})\} =
-\frac{n}{2} \log(2 \pi) - \frac{1}{2} \log (|\boldsymbol{\Sigma}|)
-\frac{1}{2} (\mathbf{z} - \boldsymbol{\mu})^{\top}\boldsymbol{\Sigma}^{-1}
(\mathbf{z} - \boldsymbol{\mu}). $$ The following codes define a function
that will compute the target log density. When performing the MH algorithm,
we can disregard the other components of the multivariate Gaussian log density
that do not depend on $\mathbf{z}$ as shown in the
R function below.
Specify the proposal (conditional) distribution
$q(\mathbf{z}^{\text{new}} | \mathbf{z}^{\text{old}})$.
Here, $\mathbf{z}^{\text{old}}$ denotes the last accepted sample in the chain and
$\mathbf{z}^{\text{new}}$ is the newly proposed (not yet accepted or rejected) sample.
There are two most commonly used types of proposal distributions, namely,
(a) independent and (b) random-walk.
Independent proposal distributions are those that do not depend on
$\mathbf{z}^{\text{old}}$, the most current accepted sample in the chain.
This means that
$$q(\mathbf{z}^{\text{new}} | \mathbf{z}^{\text{old}}) =
q(\mathbf{z}^{\text{new}}).$$
For instance,
$$q(\mathbf{z}^{\text{new}}) = \mathcal{N}_{n}
(\mathbf{z}^{\text{new}} | \boldsymbol{\mu}, \boldsymbol{\Sigma}).$$
This approach is ideal when the proposal distribution is known to
approximate well the target distribution.
Proposal distributions under the random walk approach are those that depend on
the value from the previous iteration, $\mathbf{z}^{\text{old}}$.
Moreover, the proposal distribution will be centered around
$\mathbf{z}^{\text{old}}$. For example, if the proposal distribution is the
following:
$$q(\mathbf{z}^{\text{new}} | \mathbf{z}^{\text{old}}) =
\mathcal{N}_{n}(\mathbf{z}^{\text{new}} | \mathbf{z}^{\text{old}}, \boldsymbol{\Sigma}),$$
then this means that the proposal distribution is the multivariate
Gaussian distribution with mean $\mathbf{z}^{\text{old}}$
and covariance matrix $\boldsymbol{\Sigma}$.
Note that the random walk proposal distribution above is symmetric since
$$\mathcal{N}_{n}(\mathbf{z}^{\text{new}} | \mathbf{z}^{\text{old}}, \boldsymbol{\Sigma}) =
\frac{1}{(2 \pi)^{n/2} |\boldsymbol{\Sigma}|^{1/2}} \exp \left\{
-\frac{1}{2} (\mathbf{z}^{\text{new}} - \mathbf{z}^{\text{old}})^{\top}\boldsymbol{\Sigma}^{-1}
(\mathbf{z}^{\text{new}} - \mathbf{z}^{\text{old}})\right\} $$
is equal to
$$\mathcal{N}_{n}(\mathbf{z}^{\text{old}} | \mathbf{z}^{\text{new}}, \boldsymbol{\Sigma}) =
\frac{1}{(2 \pi)^{n/2} |\boldsymbol{\Sigma}|^{1/2}} \exp \left\{
-\frac{1}{2} (\mathbf{z}^{\text{old}} - \mathbf{z}^{\text{new}})^{\top}\boldsymbol{\Sigma}^{-1}
(\mathbf{z}^{\text{old}} - \mathbf{z}^{\text{new}})\right\}.$$
This means that $q(\mathbf{z}^{\text{new}} | \mathbf{z}^{\text{old}}) =
q(\mathbf{z}^{\text{old}} | \mathbf{z}^{\text{new}})$.
Code the MH algorithm.
Initialize the chain with an arbitrary value for $\mathbf{z}_0$.
For example, $\mathbf{z}_0$ can be the zero vector.
z0 <- rep(0, n.loc)
Set the value of $\mathbf{z}_{\text{old}}$ to $\mathbf{z}_0$.
z.old <- z0
Set the number of iterations that the MH algorithm will perform.
n.epoch <- 10000
Define a matrix where we can store the values of the current vector
at every iteration.
out <- matrix(NA, nrow=length(mu), ncol=n.epoch + 1)
For $r = 1, \ldots,$n.epoch,
repeat the following steps:
Generate $\mathbf{z}_{\text{new}}$, a candidate vector to be the
next vector in the chain, from the proposal distribution.
eps <- 0.1
z.new <- z + runif(length(mu), -eps, eps)
Calculate the acceptance probability
$A$.
Since we are working with log densities, we can translate the
acceptance ratio above to its equivalent log acceptance ratio.
$$\log A = \min \left[0, \log \{p(\mathbf{z}_{\text{new}})\} -
\log \{p(\mathbf{z}_{\text{old}})\} \right].$$
Generate $u$ from the uniform distribution $U[0, 1]$.
u <- runif(n=1, min=0, max=1)
Accept $\mathbf{z}_{\text{new}}$ as the next vector in the chain
if $u \leq \alpha$. Otherwise, do not update the value of
$\mathbf{z}_{\text{old}}$.
if(log(u) <= log.A){
z.old <- z.new
}
Store the values of the current vector in the chain.
out[,r+1] <- z.old
Problems of Metropolis-Hastings Algorithm in High Dimensions
The naive MH algorithm above is not
applicable in high dimensions (Au and Beck 2001).
A more advanced MH algorithm that was shown to work efficiently in high dimensions
is called the Metropolis-Adjusted Langevin Algorithm (MALA)
(Särkkä et al. 2021;
Xifara et al. 2014).
The key innovation in MALA is the choice of the proposal distribution, which is the
most critical component for the MH algorithm to be successful. Note that the next
candidate sample in the chain is drawn from the proposal distribution. The quality of
the candidate samples drawn from the independent and random walk proposal distributions
earlier are not great since they will always be rejected by the algorithm. Under MALA,
the suggested proposal distribution is
$$q(\mathbf{z}^{\text{candidate}} | \mathbf{z}^{\text{current}}) =
\mathcal{N}_{n}\left[\mathbf{z}^{\text{candidate}} \Big| \mathbf{z}^{\text{current}}
+ \frac{h}{2} \mathbf{M} \nabla \log \{p(\mathbf{z}_{\text{current}})\}, h \mathbf{M} \right],$$
where $h$ is a user-defined step-size, $\nabla \log \{p(\mathbf{z}_{\text{current}})\}$
denotes the gradient of $\log \{p(\mathbf{z}_{\text{current}})\}$, and $\mathbf{M}$ is the
preconditioning matrix. The strength of MALA lies in incorporating the gradients of the target
when drawing the next candidate sample.
Principle Behind the Metropolis-Adjusted Langevin Algorithm
MALA was born out of the observation that simulating from the target distribution
$p(\mathbf{z})$ can be achieved by simulating realizations from a stochastic
differential equation (SDE) whose stationary distribution is the target distribution
$p(\mathbf{z})$ (Särkkä et al. 2021). In particular, the
the realizations $\mathbf{Z}_1, \mathbf{Z}_2, \ldots $ from the Langevin diffusion with the SDE
$$d \mathbf{Z}_r = \frac{1}{2} \nabla \log \{p(\mathbf{Z}_{r})\} dr + d \mathbf{W}_r,
\quad \text{ and } \quad \mathbf{Z}_0 = \mathbf{z}_0$$
will have a long run stationary distribution equal to the target distribution $p(\mathbf{z})$.
Here, $\mathbf{W} = (\mathbf{W}_r)_{r \geq 0}$ is a standard $n$-dimensional Wiener process.
A generalized version of the SDE above is available in the form:
$$d \mathbf{Z}_r = \frac{1}{2} \mathbf{M} \nabla \log \{p(\mathbf{Z}_{r})\} dr +
\sqrt{\mathbf{M}} d \mathbf{W}_r,$$
where $\mathbf{M} = \sqrt{\mathbf{M}} \sqrt{\mathbf{M}}^{\top}.$
The inclusion of $\mathbf{M}$ makes MALA more efficient in simulating $\mathbf{Z}$
with strongly correlated components (Shapovalova 2021).
1. Metropolis, Nicholas and Rosenbluth, Arianna W and Rosenbluth, Marshall N and Teller, Augusta H and Teller, Edward (1953). "Equation of state calculations by fast computing machines." The Journal of Chemical Physics, 21(6), 1087-1092. https://doi.org/10.1063/1.1699114.↩
2. Hastings, W. K. (1970). "Monte Carlo sampling methods using Markov chains and their applications." Biometrika, 57(1), 97-109. https://doi.org/10.1093/biomet/57.1.97.↩
3. Au, Siu-Kui and Beck, James L (2001). "Estimation of small failure probabilities in high dimensions by subset simulation." Probabilistic Engineering Mechanics, 16(4), 263-277. https://doi.org/10.1016/S0266-8920(01)00019-4.↩
4. Särkkä, Simo and Merkatas, Christos and Karvonen, Toni (2021). "Gaussian Approximations of SDES in Metropolis-Adjusted Langevin Algorithms." 2021 IEEE 31st International Workshop on Machine Learning for Signal Processing (MLSP), 1-6. https://doi.org/10.1109/MLSP52302.2021.9596301.↩
5. Xifara, Tatiana and Sherlock, Chris and Livingstone, Samuel and Byrne, Simon and Girolami, Mark (2014). "Langevin diffusions and the Metropolis-adjusted Langevin algorithm." Statistics & Probability Letters, 91, 14-19. https://doi.org/10.1016/j.spl.2014.04.002.↩
6. Shapovalova, Yuliya (2021). ""Exact” and approximate methods for Bayesian inference: Stochastic volatility case study." Entropy, 23(4), 466. https://doi.org/10.3390/e23040466.↩